👁️Visual_MediaCrawler - 可视化自媒体平台爬虫
(基于 MediaCrawler 项目进行改动)🕷️





免责声明:
大家请以学习为目的使用本仓库⚠️⚠️⚠️⚠️,爬虫违法违规的案件
本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
更为详细的免责声明请查看项目根目录下 ./docs/site_config/7.免责声明.md
📖 项目简介
本项目是一个前后端分离的媒体数据采集平台。它能够异步、高效、直观地采集国内主流平台的媒体数据,并将其存储在本地 SQLite 数据库中。用户可以根据需求筛选和导出 CSV/JSON 格式的数据,以便进行数据分析和提供给 BI 工具使用。 基于知名的开源项目 MediaCrawler 进行了大幅度改动,主要改动内容如下:
- 高性能 API 服务:使用 FastAPI 构建了支持异步高并发的 API 服务器,所有功能均可通过 API 接口进行调用,提升了系统的可扩展性和集成能力。
- 灵活的数据库支持:增加了 SQLite 数据库作为默认存储数据库,并编写了相应的数据库事务脚本,以兼容 MySQL 存储。同时,这种设计也更利于对其他关系型数据库的适配,为用户提供了更多数据存储选择。
- 直观的用户界面:构建了前端服务,提供了 "数据爬取" 和 "数据展示" 两个核心界面,使得操作更加便捷直观,充分对齐了项目的核心功能,提升了用户体验。
- 现代化开发环境:使用
uv管理项目环境,并将 Python 版本升级到 3.13.5。同时,同步升级了所有依赖包以适配新版本,并对过时的代码进行了更新,确保了项目的稳定性和前瞻性。 - 改动的命令行与功能:对命令行工具及其功能进行了更新,增加了以下新参数(为API服务而设计):
--max_count:用于控制单次爬取的上限条数。--task_id:引入了 "任务(每次)ID" 的概念,以 "每次任务" 为数据管理理念,并适配了 API 服务,方便用户追踪和管理每次爬取任务。--storage_type:将爬取数据保存至SQLite或MySQL数据库
声明:本项目改动部分的代码,70%+通过AI编程实现,其中存在未完全Review的部分,若在使用中出现问题请提交ISSUES,开发者会积极解决
😶🌫️ 前端展示
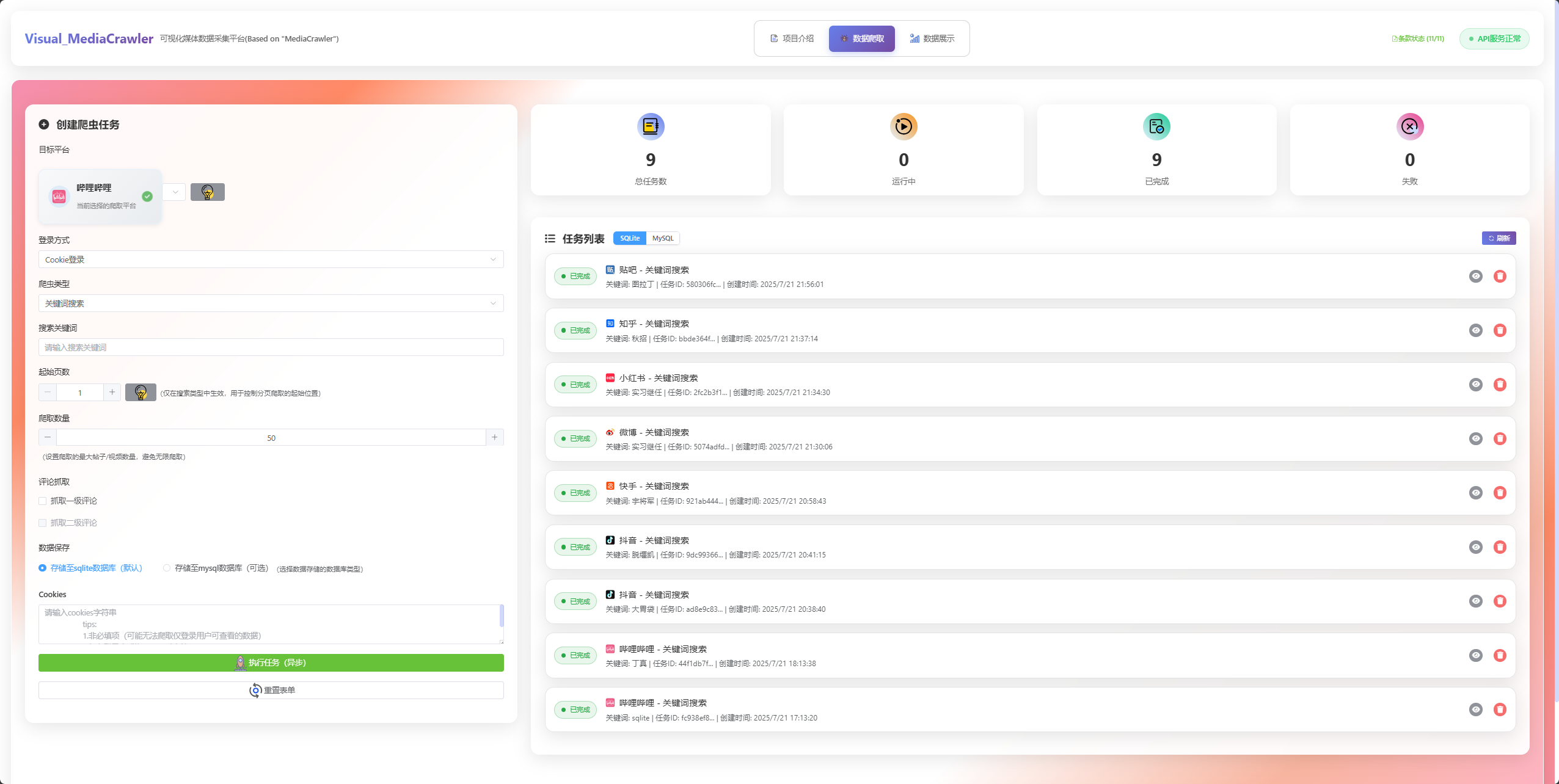
🕷️ 数据爬取页面
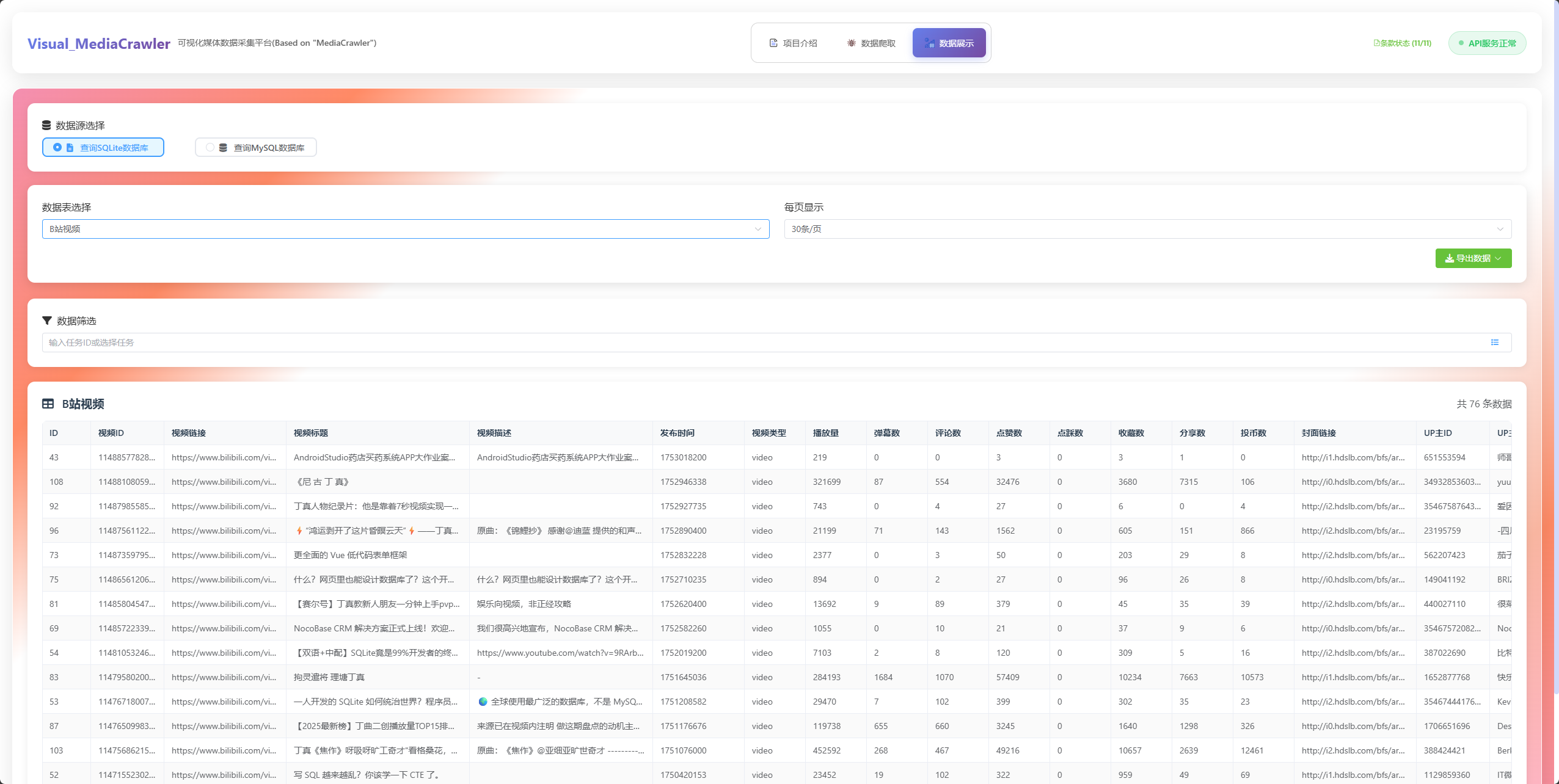
📊 数据展示页面
🦄 支持的平台
本项目支持以下主流媒体平台的数据采集(与源项目"MediaCrawler"的支持平台一致):
- 小红书 (xhs):支持搜索、详情页、创作者数据采集
- 抖音 (dy):支持视频搜索、详情页、创作者数据采集
- 快手 (ks):支持视频搜索、详情页、创作者数据采集
- 哔哩哔哩 (bili):支持视频搜索、详情页、UP主数据采集
- 微博 (wb):支持微博搜索、详情页、用户数据采集
- 百度贴吧 (tieba):支持帖子搜索、详情页数据采集
- 知乎 (zhihu):支持问答搜索、详情页、用户数据采集
登录方式
- 二维码登录 (qrcode):通过扫描二维码进行登录
- 手机号登录 (phone):使用手机号和验证码登录
- Cookie登录 (cookie):使用已有的Cookie信息登录
数据存储
- SQLite 数据库:默认存储方式,轻量级本地数据库
- MySQL 数据库:可选的数据同步方式,支持企业级数据存储
- CSV/JSON 导出:支持将数据导出为常见的数据格式,便于数据分析
🚀 快速开始
环境要求
- Python 3.13.5+
- Node.js 16+
- uv (Python包管理器)
安装依赖
bash
# 安装Python依赖
uv sync
# 安装前端依赖
cd frontend
npm install启动服务
启动后端API服务
bash
.venv\Scripts\activate # 激活虚拟环境
uvicorn api:app --host 127.0.0.1 --port 10001 --reload # 启动API服务 方式1
uv run ./api/api.py --host 127.0.0.1 --port 10001 # 启动API服务 方式2- http://127.0.0.1:10001 # 在浏览器中打开前后端一体项目(仅前端资源被构建时)
- http://127.0.0.1:10001/api # API服务接口地址
- http://127.0.0.1:10001/docs # API服务接口文档地址
启动前端开发服务
bash
cd frontend
npm run dev- http://127.0.0.1:10002/ # 在浏览器中打开前端开发服务页面
使用说明
- 访问前端界面进行可视化操作
- 或直接调用API接口进行数据采集
- 查看数据库中的采集结果
- 根据需要导出CSV或JSON格式的数据
🤔 技术特性
- 异步高并发:基于FastAPI和asyncio实现高性能数据采集
- 模块化设计:清晰的项目结构,易于维护和扩展
- 多平台支持:覆盖国内主流媒体平台
- 灵活的数据存储:支持SQLite和MySQL双重存储
- 任务管理:完整的任务生命周期管理
- 数据导出:多种格式的数据导出功能
- 前端可视化:直观的Web界面操作
📖 许可证
本项目基于开源许可证"NON-COMMERCIAL LEARNING LICENSE 1.1"(继承于源项目"MediaCrawler"的许可证)发布,仅供学习和研究目的使用。使用时请遵守相关平台的使用条款和robots.txt规则,合理控制请求频率,避免对目标平台造成不必要的负担。
🤝 贡献
欢迎提交Issue和Pull Request来帮助改进项目。在贡献代码前,请确保遵循项目的代码规范和最佳实践。