Visual_MediaCrawler使用方法
创建并激活 python 虚拟环境
如果是爬取抖音和知乎,需要提前安装nodejs环境,版本大于等于:
18即可
shell
# 进入项目根目录
cd Visual_MediaCrawler
# 创建虚拟环境(pip 或 uv)
python -m venv .venv
uv venv .venv
# macos & linux 激活虚拟环境
source .venv/bin/activate
# windows 激活虚拟环境
.venv\Scripts\activate安装依赖库
shell
pip install -r requirements.txt # 使用PIP安装依赖库
uv sync # 使用UV安装依赖库(推荐)安装 playwright浏览器驱动
shell
playwright install数据库初始化
- 支持关系型数据库SQLite或MySQL中保存(需要提前创建数据库)
- 执行
python db_init.pyoruv run db_init.py初始化数据库数据库表结构(只在首次执行) - 注意 首次执行MySQL数据库初始化脚本时,需要确保 1.MySQL连接配置正确(位于./config/db_config.py),包括数据库主机、端口、用户名、密码等。 2.已经创建好MySQL数据库。
- 详细的数据库初始化过程可参照 2.数据库初始化指南.md
- 执行
运行项目
在项目根目录下启动API服务
# 在项目根目录下
.venv\Scripts\activate # 激活虚拟环境
uvicorn api:app --host 127.0.0.1 --port 10001 --reload # 启动API服务 方式1
uv run ./api/api.py --host 127.0.0.1 --port 10001 # 启动API服务 方式2
http://127.0.0.1:10001 # 在浏览器中打开前后端一体项目(仅前端资源被构建时)
http://127.0.0.1:10001/api # API服务接口地址
http://127.0.0.1:10001/docs # API服务接口文档地址在项目根目录下启动前端服务
cd ./frontend
npm install
npm run dev
http://127.0.0.1:10002/ # 在浏览器中打开前端服务页面在项目根目录下启动前后端一体服务(推荐)
cd ./frontend # 进入前端目录
npm install
npm run build # 构建前端项目静态资源
cd .. # 回到项目根目录
uvicorn api:app --host 127.0.0.1 --port 10001 --reload # 启动API服务 方式1
uv run ./api/api.py --host 127.0.0.1 --port 10001 # 启动API服务 方式2
http://127.0.0.1:10001/ # 在浏览器中打开前后端一体项目(仅前端资源被构建时)免责声明
免责声明:
大家请以学习为目的使用本仓库,爬虫违法违规的案件:https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China
本项目的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
😶🌫️ 前端展示
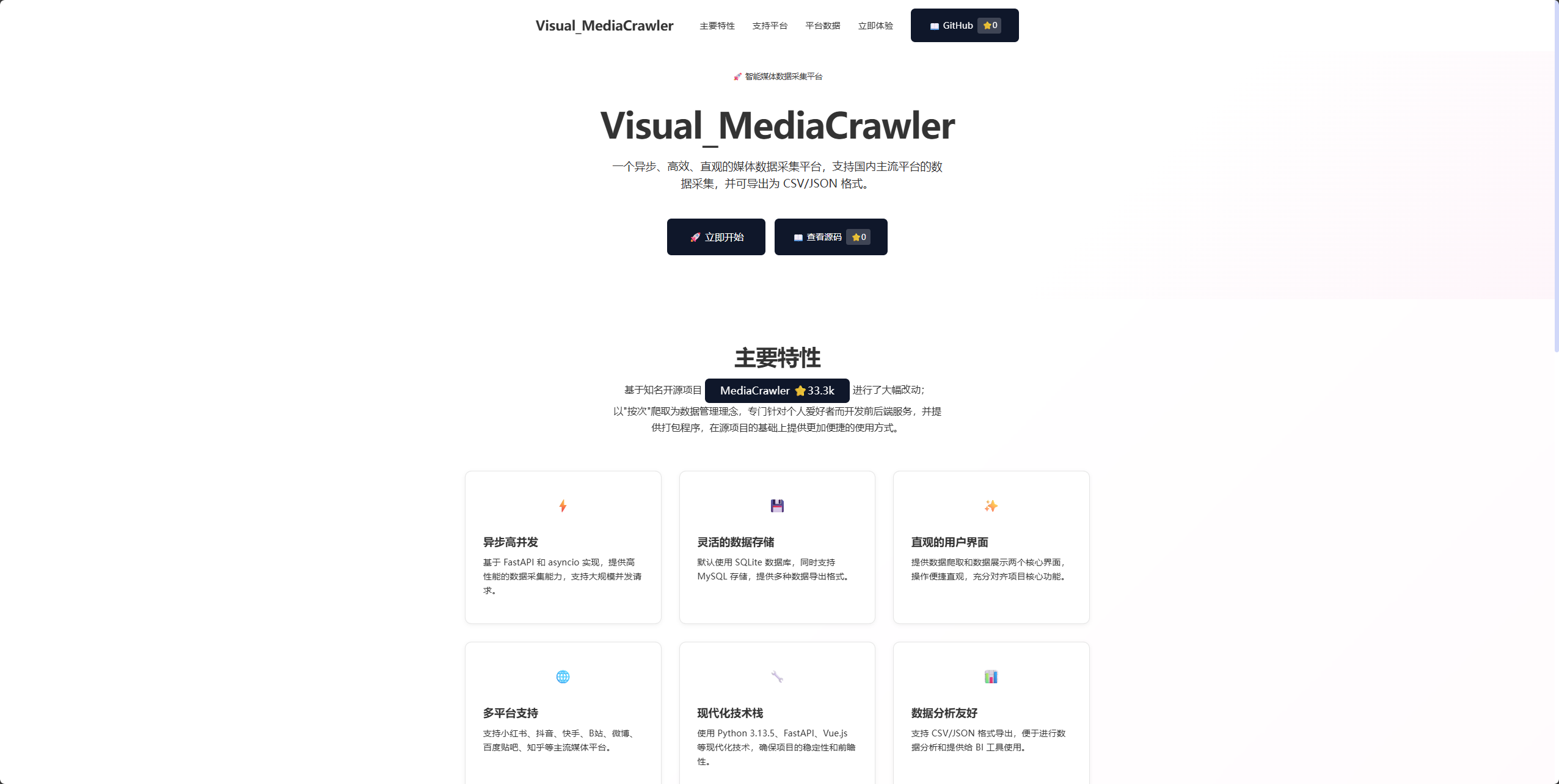
📱 项目介绍页面
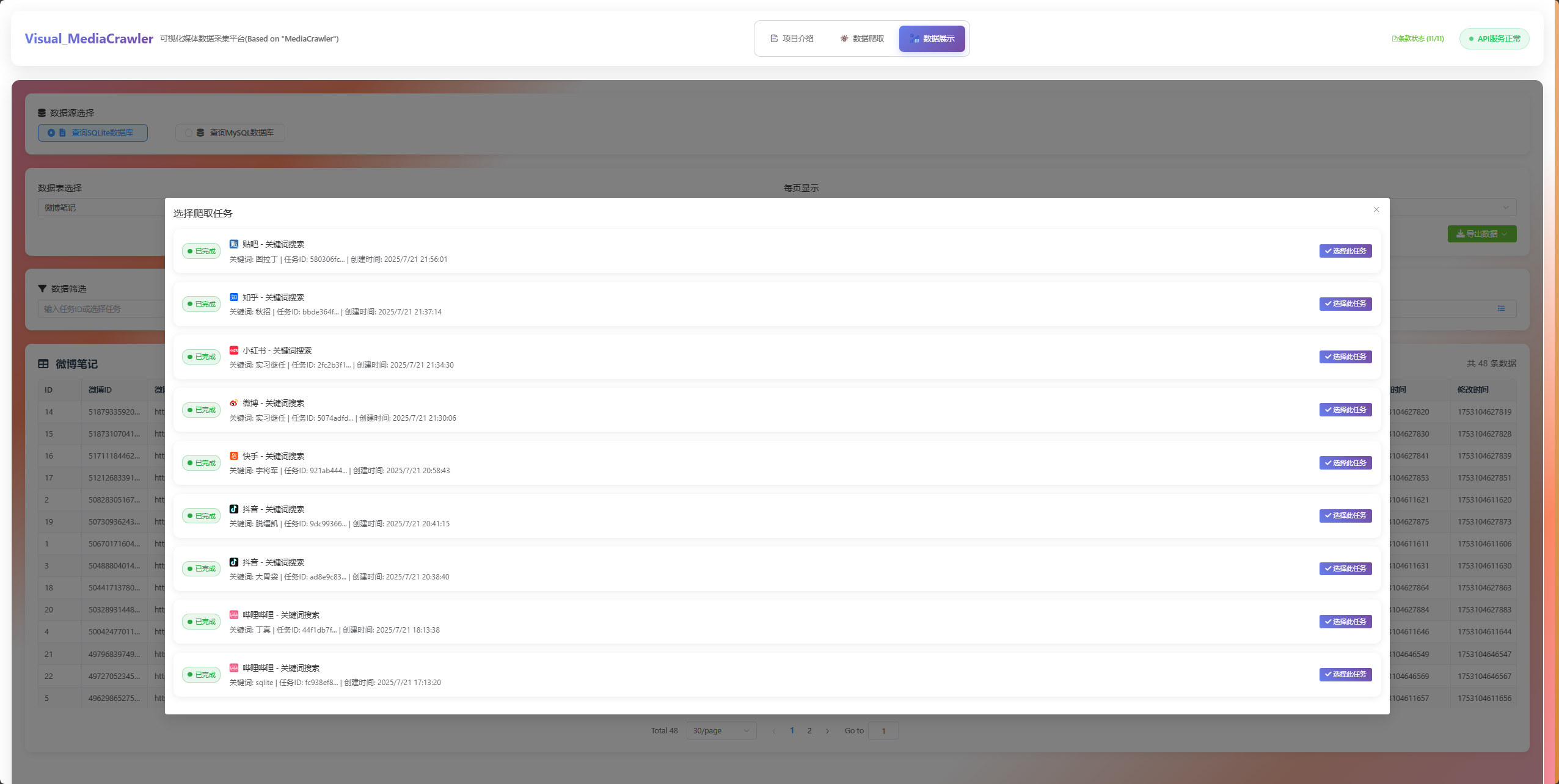
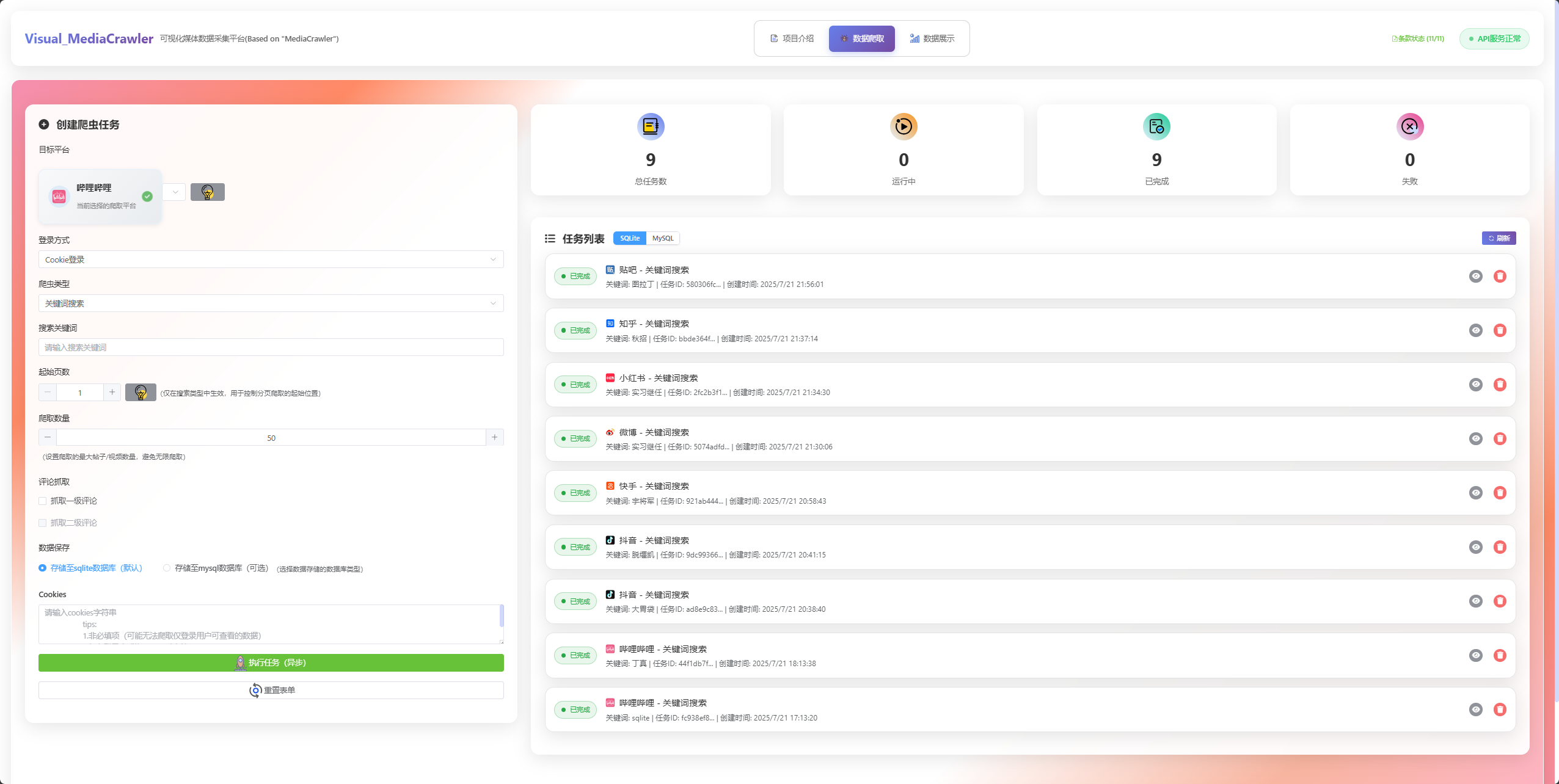
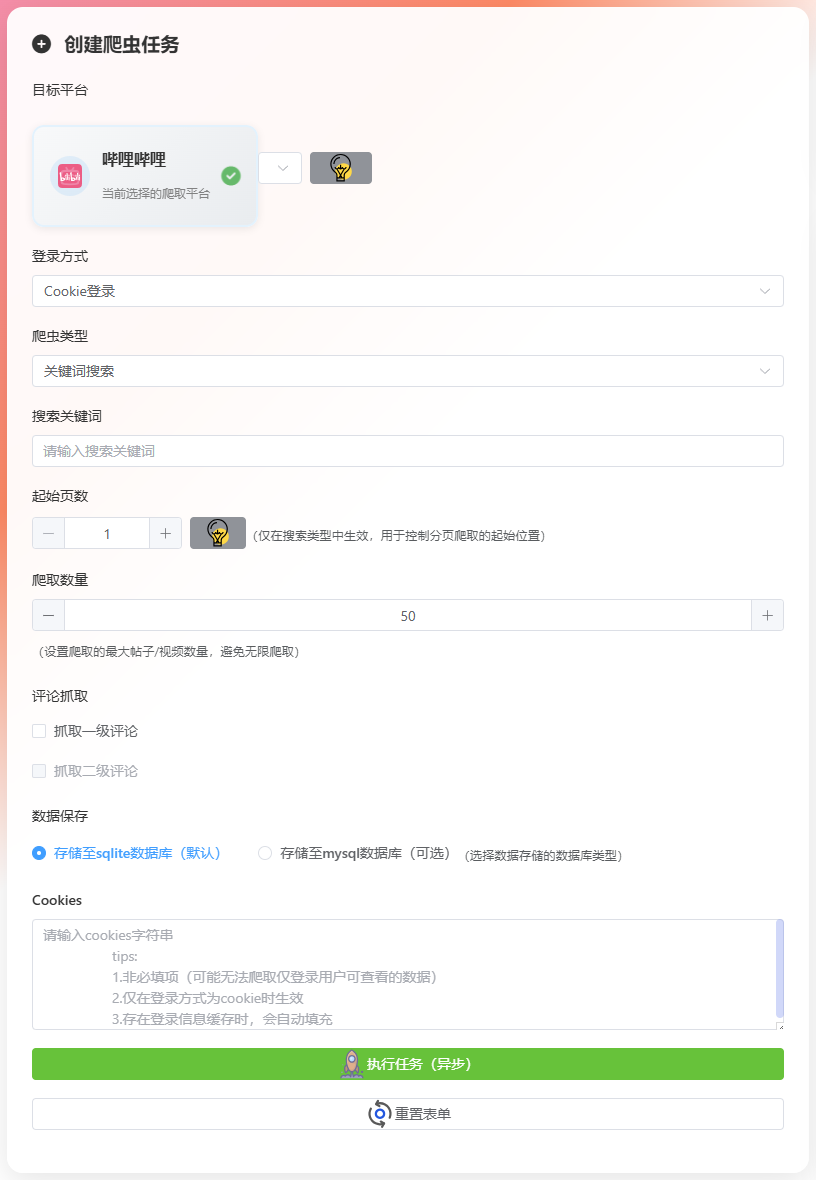
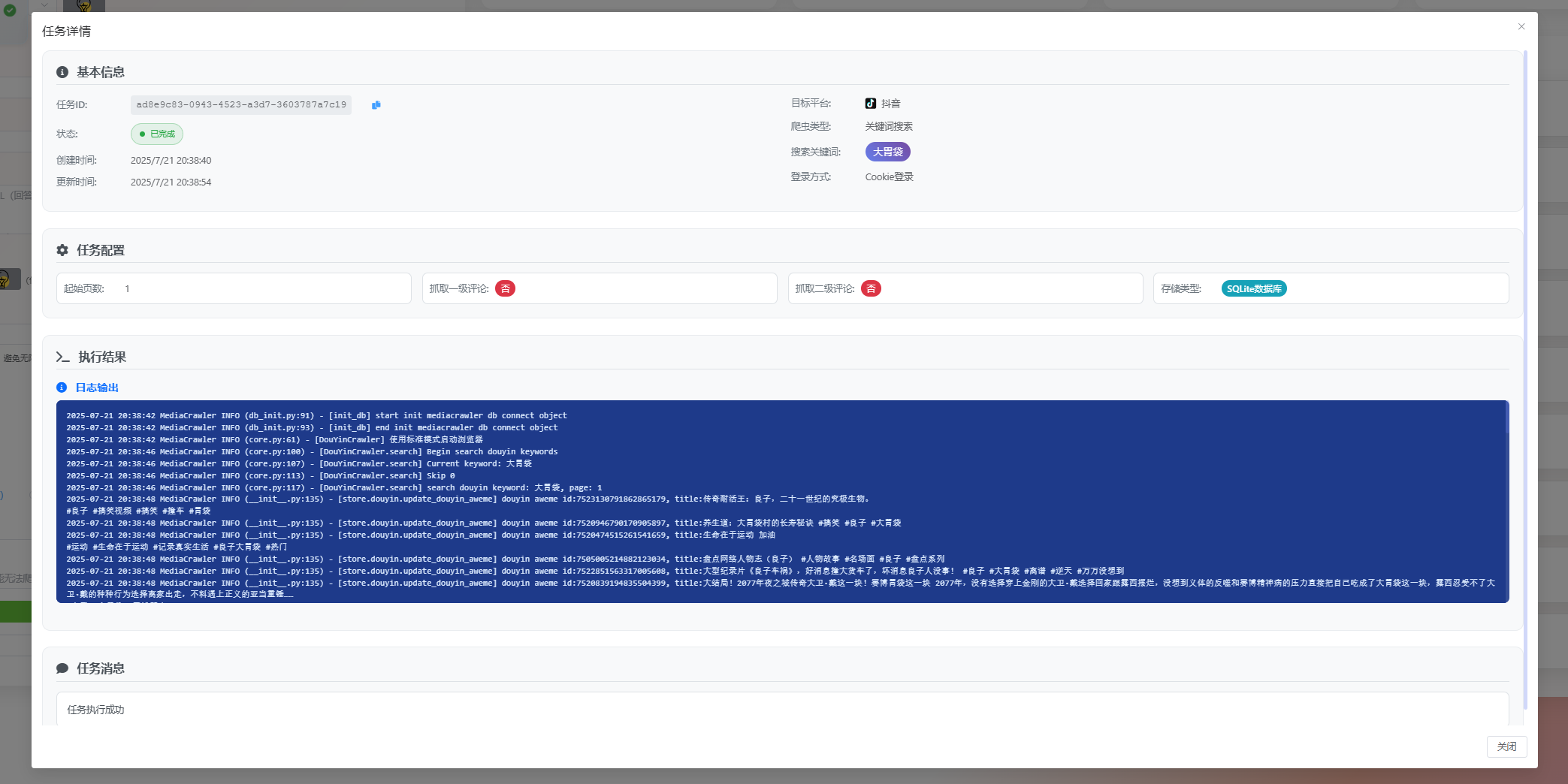
🕷️ 数据爬取功能
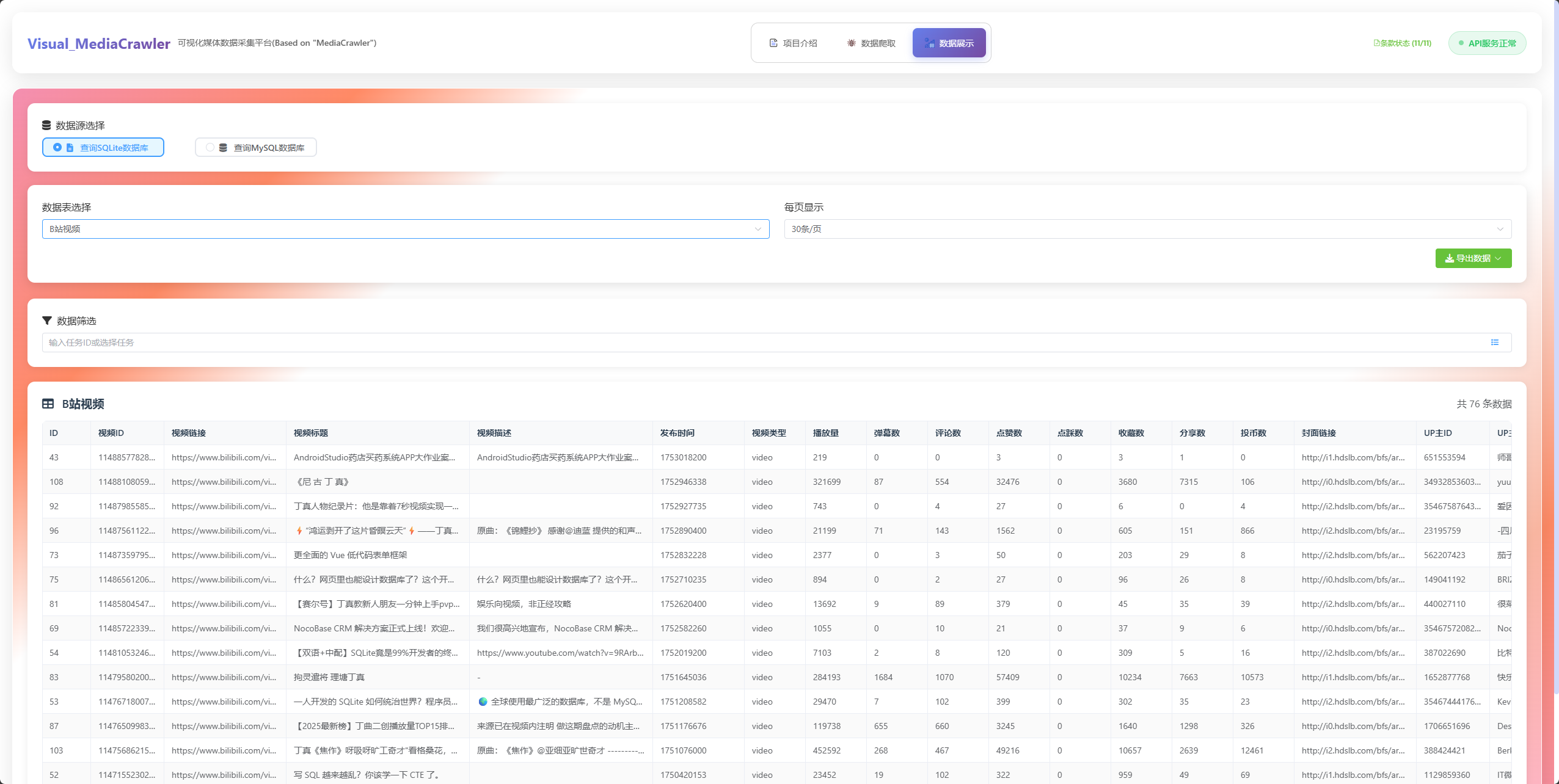
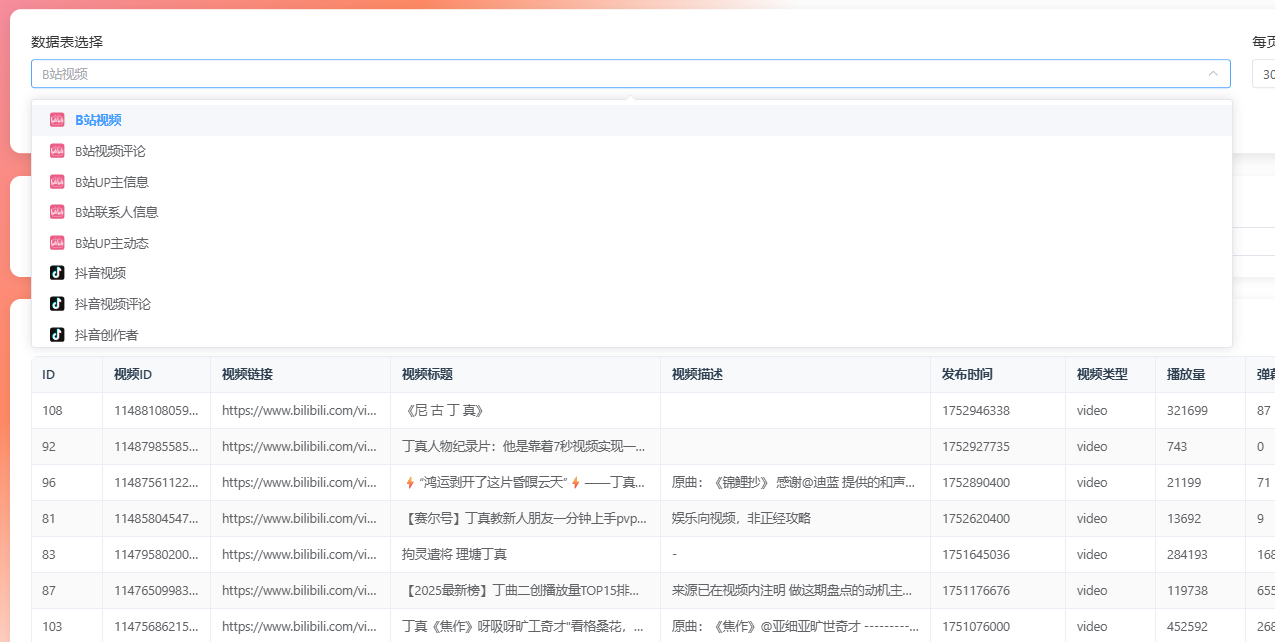
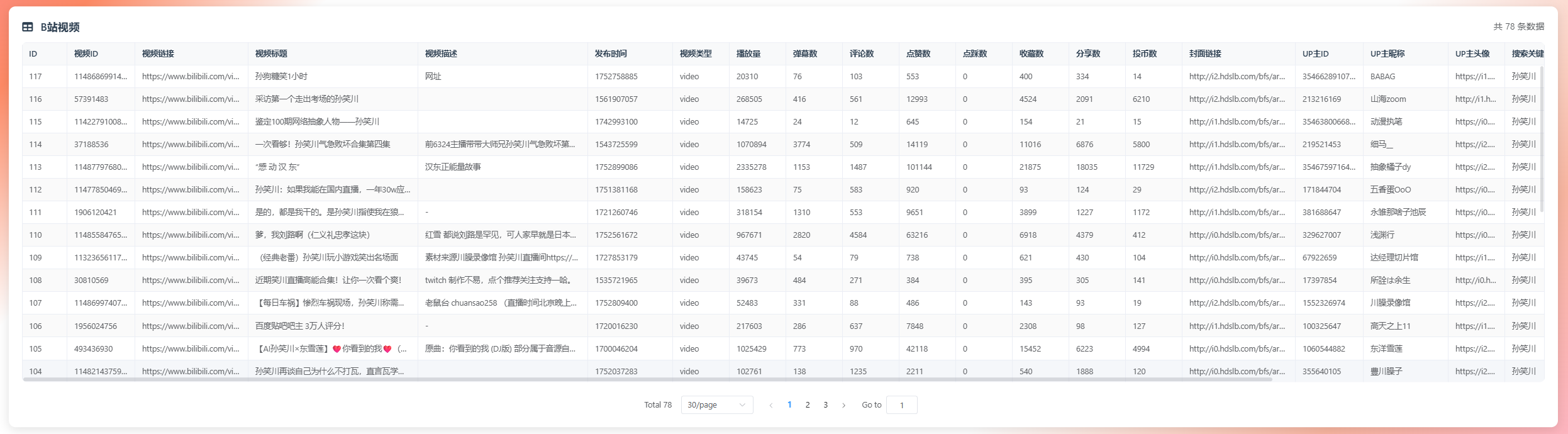
📊 数据展示功能